
Tableau's New Data Model & Relationships

The latest version of Tableau, 2020.2, introduces a game-changing
new data model, which is significantly different from the way the data model
has worked in the past. In this blog, I’m going to dive a bit into how this new
data model works compared to the previous model, as well as some of the
problems it solves.
A few notes before we begin. First, if you’re not yet
familiar with the new data model, I’d suggest that you start by watching the short
video on How Relationships Differ from Joins. It will give you an overview of the new concept
of “relationships” and generally how they differ from joins. If you’re
interested in digging a bit deeper, you can also read The Tableau Data Model and Relationships, Part 1: Introducing New Data Modeling in Tableau. Second, in order to understand exactly what the data
model is doing, we’re going to be looking at the SQL generated by Tableau.
While I’ll be simplifying this SQL a bit for readability, I am assuming some
previous understanding of SQL. If you do not have a SQL background and want to
learn, feel free to check out my series on SQL for Tableau Users. Finally, these tests will be performed using my publicly-available
SQL Server Superstore database. If you’d like to replicate these tests
yourself, the connection information is available on the SQL for Tableau Users
blog shared above.
The Old Data Model
Using the old data model (pre-2020.2), you had to
specify each table and tell Tableau exactly how to join these tables together. For
instance, here’s a simple data model joining Orders to People
based on the Region field.
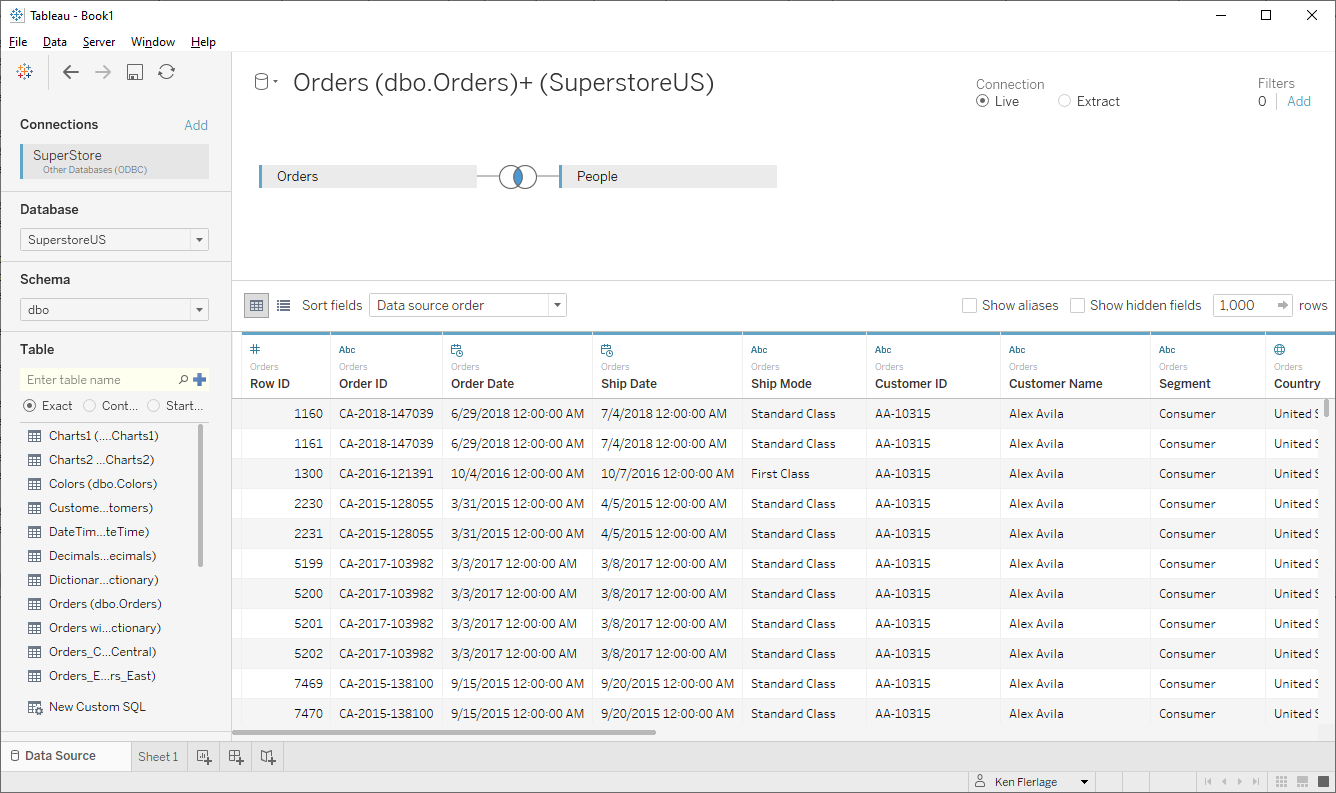
In order to demonstrate how this is communicating with the
back-end database, let’s look at the SQL that is executed:
SELECT *
FROM [Orders]
INNER JOIN [People]
ON [Orders].[Region] = [People].[Region]
Any visual we create in Tableau will always use this base
SQL, joining Orders to People, even if we don’t show any of the
fields from People. For instance, let’s create a very simple bar chart
showing Sales by Customer. This will generate the following SQL:
SELECT [Customer Name], SUM([Sales])
FROM [Orders]
INNER JOIN [People]
ON [Orders].[Region] = [People].[Region]
GROUP BY [Customer Name]
The only two fields used in our view are the dimension, Customer
Name and the measure, Sales, both which come from the Orders table—we
are not using any fields from People. Yet, the SQL generated by Tableau
still includes the join to the People table.
This approach has many drawbacks. For one, it’s unnecessarily
joining tables, which will be less performant than simply selecting data from
the one table that is actually required. A second drawback is that it could,
potentially retrieve more records than it actually needs. To demonstrate this,
let’s look at a scenario where we have a one-to-many relationship between our
tables. In my database, I have an alternate Person table called Person_Multiple:

As you can see, this table has two people for each region.
When we use this in our data model, it executes a similar SQL statement as shown
above. But, because there are two people for each region, each record in Orders
is duplicated. The result set is 19,988 records, as opposed to the 9,994
records in Orders. If you’re dealing with millions of records, this
duplication could prove to be a huge constraint. But this size difference is
only part of the problem—aggregations are also impacted by this data duplication.
For example, let’s create that bar chart showing Sales by Customer again. It executes
pretty much the same SQL (except using People_Multiple instead of People),
but because of the record duplication, our resulting Sales aggregates are doubled.
The typical solution to this problem is the use of a Level-of-Detail
calculation (see use case # 1 in 20 Uses for Level-of-Detail Calculations). Unfortunately, LODs are a bit tricky and not
readily accessible to new users of Tableau. Additionally, some people may not
even realize that their join has led to data duplication and, thus, don’t know
that they need to address the problem.
So, even with this very simple data model, we’re left with three
key problems:
1) Over-complicated SQL – Unnecessary over-complication
of our SQL, which will have a performance impact.
2) Duplicated Records – More records than we actually
need or want.
3) LOD Requirements – The need to use LOD calculations
to address data duplication in aggregates.
The key point here is that the old data model is “set-in-and-forget-it”.
You create the basic structures, then all of the SQL executed will pull
from that same structure. The SQL may retrieve different fields and may perform
different types of aggregations, but the FROM clause will always include all
the tables in your model, joined exactly how you’ve instructed it to do so.
Note: As Zen Master, Tamas Foldi, pointed out to me, my above statement is not exactly true (I should know better than to use the word "always" when discussing anything related to Tableau as it seems there is "always" another option 😉). If you use the "Assume Referential Integrity" option, Tableau will eliminate (cull) the join when that table is not required on the view. This will, of course, result in a more efficient SQL statement. But, you must also be careful—if you select this option and your database does not have referential integrity, it could produce inaccurate results. For more information on this feature, see Assuming Referential Integrity for Joins.
Note: As Zen Master, Tamas Foldi, pointed out to me, my above statement is not exactly true (I should know better than to use the word "always" when discussing anything related to Tableau as it seems there is "always" another option 😉). If you use the "Assume Referential Integrity" option, Tableau will eliminate (cull) the join when that table is not required on the view. This will, of course, result in a more efficient SQL statement. But, you must also be careful—if you select this option and your database does not have referential integrity, it could produce inaccurate results. For more information on this feature, see Assuming Referential Integrity for Joins.
The New Data Model
This is where the new data model is different. The use of “relationships”
means that Tableau will be generating a unique SQL statement for every view you
create. It will no longer include all the tables in your model. Instead, it
analyzes the fields used in your view and creates a SQL statement that is
tailored to only retrieve the data you actually need. Let’s take a look.
Here’s the data model using relationships. Notice that there
is no Venn diagram showing the join type. That’s because we no longer have to
specify the join type. We simply define the relationships between the two tables—in
this case, the Region fields. But, at this point, these tables remain
independent. Tableau is not building a base SQL statement to use throughout the
workbook as with the old data model. We’re just establishing a loose tie
between the table that will be used when Tableau generates the view-specific
SQL.

Let’s, once again, build our Sales by Customer bar chart. Using
the new data model, our SQL will look like this:
SELECT [Customer Name], SUM([Sales])
FROM [Orders]
GROUP BY [Customer Name]
Tableau has identified that none of the fields from People
are used in this view and has, therefore, excluded it from the SQL. This is a
concept that Tableau refers to as “join culling”—basically a process by which
the data engine removes unnecessary joins.
But what happens if we use a field from People in our
view? For example, what if we only keep records for the Person, Anna
Andreadi? That will generate the following SQL:
SELECT [Customer Name], SUM([Sales])
FROM [Orders]
INNER JOIN [People]
ON [Orders].[Region] = [People].[Region]
WHERE [Person] = 'Anna Andreadi'
GROUP BY [Customer Name]
Because we’ve used a field from the People table,
Tableau has generated a join using the relationship we established in the data
model.
We can immediately see the benefit of this on-the-fly
generation of SQL as it ensures that we’re only asking the database for the
data we actually need. This will, inevitably, lead to better query performance,
addressing the first problem with the old data model.
But how does the new data model impact our other two problems—duplicated
records and the need for LODs—which are caused by one-to-many relationships? The
new data model stores each table independently, rather than joining them
together then storing the data. Thus, data duplication is not really a problem
from a data size standpoint. But it could be a problem when it comes to
aggregation. To understand this, let’s change our data model to use the People_Multiple
table instead of People:
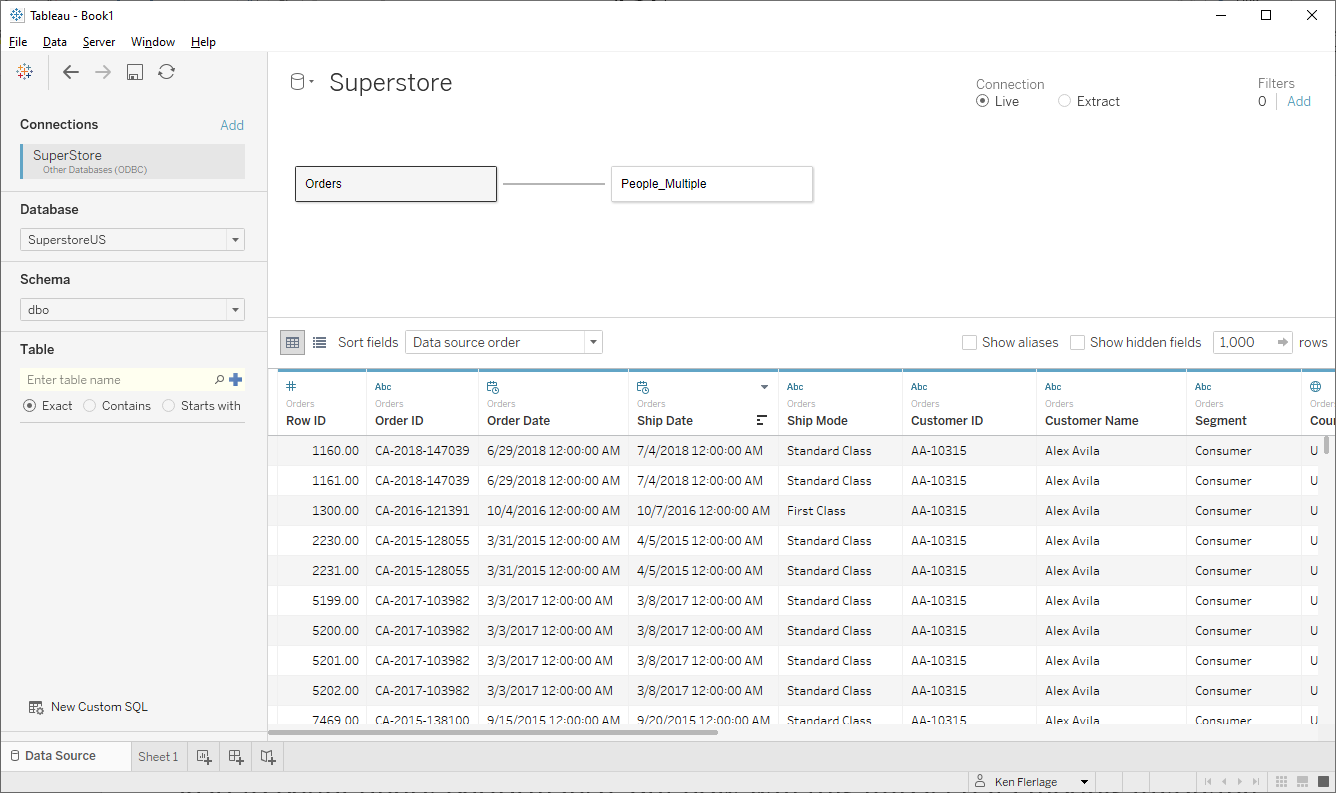
Now let’s build our simple Sales by Customer bar chart
again. When we do this, it executes the following SQL:
SELECT [Customer Name], SUM([Sales])
FROM [Orders]
GROUP BY [Customer Name]
That looks familiar! Again, because the view does not
include any fields from People_Multiple, Tableau culls the join. And the
beauty of this simple SQL statement is that SUM(Sales) will not be duplicated—this
will give us the actual value, without the need for an LOD calculation.
But what happens when we do use fields from People_Multiple?
Will that break everything and force us to use an LOD? Let’s add a filter on Person
= ‘Central Person 1’. That executes the following
SQL:
SELECT [Customer Name], SUM([Sales])
FROM [Orders]
INNER JOIN (
SELECT
[Orders].[Region]
FROM [Orders]
INNER JOIN
[People_Multiple]
ON
[Orders].[Region] = [People_Multiple].[Region]
WHERE
[Person] = 'Central Person 1'
GROUP BY
[Orders].[Region]
) AS [Table 1]
ON [Orders].[Region] = [Table 1].[Region]
GROUP BY [Customer Name]
As you can see, this query is a bit more complex than any we’ve
seen before. But, that’s not necessarily a bad thing. Tableau has realized that
we have a one-to-many relationship in our table, so it avoids a direct join between
the Orders and People table because that would cause duplication.
Instead, Tableau generates the following sub-query:
SELECT [Orders].[Region]
FROM [Orders]
INNER JOIN [People_Multiple]
ON [Orders].[Region] = [People_Multiple].[Region]
WHERE [Person] = 'Central Person 1'
GROUP BY [Orders].[Region]
This query joins Orders and People returning
only the Region—the field upon which our table relationship is built.
The result of this specific SQL is a single column and row:

It then joins that back to the Orders table and sums
up the sales. Because the SQL avoids directly joining the two tables, we do not
experience any data duplication and the aggregation returns the accurate value,
without the need to perform complex LOD calculations. Pretty cool, eh!!
Summary
We’ve only just scratched the surface of the new data model,
but I hope that you now have a better understanding of how it works and,
particularly, how it’s different from the old data model. Make no mistake about
it—this is a game-changing feature. It introduces a level of intelligence into
the data model that simply did not exist before; it eliminates a number of
common problems—specifically when dealing with one-to-many relationships; and
it will make Tableau easier than ever for new users. I’m really excited about
this feature and can’t wait to start using it.
Note: I was recently invited to do a presentation on the New Data Model for VizConnect. This was basically a video version of the blog, so if you prefer video, you can find it here:
Note: I was recently invited to do a presentation on the New Data Model for VizConnect. This was basically a video version of the blog, so if you prefer video, you can find it here:
Ken Flerlage, May 6, 2020






















Great article. Do you foresee the use of LODs will substantially decline due to the new Data Model?
ReplyDeleteIt will definitely reduce the need for LODs, particularly since one of the most common use cases for LODs are to eliminate the impact of duplicate records. However, LODs have a ton of other use cases and I believe many of them will still be valid. If you look at my 20 Use Cases for LODs blog, I think you'll see that most will still have a place, even with the new data model.
DeleteHi Ken, thanks for the "early bird" blog which analyzes and discusses the new data model. I would rank this improvement as the secondly most important progress which just follows "Level of Detail Expressions" function, which was added in Tableau 9. You are right. More tests and practices are needed to see if there will be no interfere with LOD, filters and other Tableau concepts. I have a concern. I think that this new model will not work with the custom SQL data sources, which the joins are fulfilled by SQL instead of diagram links in Tableau. In the real project, especially when we need to join more than two tables, we mostly use custom SQL as data source instead of table diagram links. That might still be a limitation. Anyway, I am happy to see that Tableau has started to think about this important thing. In my opinion, after the LOD introduction in 5 years ago, there is no very big improvement ever since (maybe still have some very good but not key improvement, for example, cross join, set and parameter actions, etc).
ReplyDeleteThanks for all your blogs(with Kevin).
Michael Ye
Hi Michael. The good news is that Tableau has not eliminated the old way. There is not a physical layer and a logical layer. The logical layer deals with relationships, but the physical layer is the way it's always worked. So, I suspect that custom SQL will just operate at the physical layer. You can then add an additional logical layer on top of that, if desired. And getting to the physical model is just a couple of clicks.
DeleteThanks for this post Ken - its a good first look into this pretty dramatic change. I haven't had a chance to play with 2020.2 yet - how or where do you define or edit the 'relationships' that Tableau uses to create this on-the-fly SQL for each worksheet or view? It seems cool, but also a little worrying, My admittedly somewhat pessimistic concern is always when an automated system tries to 'help' it will quite often do the exact thing you don't want. I'm hoping they've left in the manual override switch and you can still expressly define how you want the data to be linked if the automated query is returning incorrect results. Also how do you see the SQL that's being generated? Do you still have to generate a performance recording or pull it from the logs? I've been hoping for years Tableau would add a 'view query' option - this seems like an necessity now in order to verify results are accurate. Thanks!
ReplyDeleteYou easily edit the relationships right in the data model. This "logical" model is now the default, but you can get to the "physical" model (the old way) through a couple of clicks. So, if you are uncomfortable with the new data model, you can use the old way. I capture the SQL by placing a trace on my SQL Server database. There are other ways to do this, but this is the method I personally use. And I agree--a "Show Query" option would be great, particularly with this new setup.
DeleteMy way to view the SQL query is using Tableau Log Viewer (https://github.com/tableau/tableau-log-viewer) to trace httpd.log. By highlighting/filtering "query-begin" and "query-end" with Live mode in Tableau Log Viewer, you can lively see what SQL statements was actually executing.
DeleteLove that every new release has such great stuff packed in. As an ESRI user there's a lot to play with.
ReplyDeleteFor this post, how will this new process impact Extracts? My understanding is that no matter how complicated the SQL, once extracted into a hyper DB it's all the same. Will this change anything for us extract heavy users?
I don't know a lot about hyper under the covers, but it's a database like any other and there is a need to communicate with it via a SQL. So, the impact should be pretty similar. Of course, hyper is really fast and sits right next to the workbook, so it's performance is really good, even with poorly optimized SQL. Thus, the impact may not be that noticeable.
Deleteyou can still aggregate tables (which is the default) for each logical tables. if you move your joins inside a logical table, the behavior is the same as in pre2020.2
DeleteTamas, what are your thoughts on the performance impact? I mean, I assume it's going to work the same way in that it formulates a new query each time (when using the logical model). Would you expect any performance impact? My gut tells me that it wouldn't be that noticeable with most reasonably sized extracts, but I'm really not sure. Would love your thoughts...
DeleteOriginal comment was prior to download and playing. So far, no noticeable performance impact on legacy queries. However, I'm frequently having to blend many data sources and so this really is a game changer for my work flow.
DeleteMy new big question is whether this would somehow enable a row level security table using extracts as row duplication was always holding me back. Hmm.... Great stuff.
Hey Ken, does this new feature only affect new viz's going forward or does Tableau somehow 'refactor' existing/old viz's as well so that they perform better?
ReplyDeleteOld workbooks will continue to work the same way as they always have. The new data model exposes two layers--the physical layer and the logical layer. Old fashioned joins can still be created using the physical layer. If you open an old workbook, you'll see the logical layer, but the joins will still be set up at the physical layer. You can get to that layer with a couple of clicks.
DeleteThanks much Ken for your crisp and clear explanation of the new data model and I can foresee the ease on complex data models build by self service consumers. Definitely a game change in the Tableau data model world. As always, I admire your posts.
ReplyDeleteThank you! 😊
DeleteHi Ken - you might want to link this great blog post from your post as well - went live this week: https://www.tableau.com/about/blog/2020/5/relationships-part-1-meet-new-tableau-data-model
ReplyDeleteNancy Matthew (tech writer at Tableau)
You beat me to it, Nancy. I was just about to add a link to it. Thanks!
DeleteHi Sir,
ReplyDeleteThanks for the great post. I just wonder how it is possible to use relationships when you have different level of details data sources. For instance, in a common blending scenario that is I have sales data on daily level, and target quota data on monthly level, I try to compare my monthly sales (aggregated to month from day) with monthly target quota data.
Sales data has Category, Order ID, Product Name, Order Date columns.
Quato data has Category, Target, Month of Order Date columns.
How can I achieve a monthly level comparison?
Good question. Without seeing your data, I can't be sure how this will work. Tableau has noted, however, that the new data model does not yet handle two fact tables unless they are joined together via a common dimension (see the "Multi-fact analysis" section of https://help.tableau.com/v2020.2/pro/desktop/en-us/datasource_datamodel.htm). It sounds like you may have this scenario (or something similar) so it may not address your level of detail problems in this case. Of course, this is just version 1 so keep an eye out--I have no idea if they intend to address this, but I'm sure they'll be making continued improvements over time.
DeleteI should note that I haven't dug into this in detail, so I'm not 100% about what I'm about to say, but I believe I have it correct...
ReplyDeleteBy default, Tableau stores each "logical table" separately in the extract. Are you 3 SQL statements included in one logical table (with physical joins connecting them) or are they each their own logical table? If the latter, then Tableau will store them each separately within the extract. When the extract refreshes, it will execute each custom SQL separately and refresh each logical table in the extract. At that point, your SQL is done--it's only used for the extract refresh. However, when you use these extracts in a workbook, Tableau has to communicate to them and will use SQL to do that (acting as each is it's own table). At this point, it should be leveraging the new data model to determine how to build those SQL statements. A key point is that Tableau always had to execute SQL to communicate with extracts--it's really just another database--so this is not really creating extra load on the Tableau Server. It's just formulating better SQL statements.
Oh I didn't realize that was you, Susan! :)
ReplyDeleteYes, I think you have it correct. The size of the extract will depend on a number of different factors. If you perform physical joins, then if there is a one-to-many relationship, then data in one table will be duplicated, creating a larger extract. Whereas, if you relate them logically, the extract stores each set of data separately, so that extract should be smaller. Of course, they could also change things about extracts, compression, etc. from version to version so that may not always be exactly the case.
So nice of you to remember me Ken! Thanks so much for your help with this; I feel I understand what's happening a lot better now. I can see how the new logical layer can be really helpful as we design our published datasources, allowing us to provide more tables that won't merge into a billion-row denormalized table at extract time. Thanks so much!
ReplyDeleteOf course I remember you!! Yes, I think it's going to make our lives so much easier. And just think of how much easier it will be for newbies. You no longer even really need to understand the concept of a join, which is pretty cool.
DeleteHi Ken
ReplyDeleteOn the topic of join culling which Tamas already corrected you on. While an Inner join + "Assume referential integrity" will cull the joins in the statement passed to the underlying database, most databases will cull a Left Join on a key field automatically if you are not selecting anything from the right table.
Example:
You have a fact sales table called dbo.Sales and a dimension table called dbo.SalesPeople.
If you set up an "old" data model with the fact first and the dimension table to the right, and do a left join, tableau might pass a query like this to the underlying database:
SELECT SUM(1) as [Number of records]
from dbo.Sales sales
left join dbo.SalesPeople SalesPeople
on Sales.SalesPeopleID=SalesPeople.SalesPeopleID
However, if the SalesPeopleID is the Primary Key for the SalesPeople table, any good RDBMS will now that a left join like the one above will lead to neither removal nor duplication of fact-table rows, and since you are not using any fields from the dimension table in your select, the query optimizer will simply not join the two tables.
You do not need to setup referential integrity in your database for this to work (at least not in SQL-Server)
A great article. Imho, if you are going to be fair to the old Data Model, "WHERE [Person] = 'Central Person 1'" will eliminate replication of the rows. The problem will arise with two persons like WHERE [Person] = 'Central Person 1' OR [Person] = 'Central Person 2'
ReplyDeleteCorrect me if I wrong.
Many thanks for the knowledge!
Yep, you're right. That was a poor example, wasn't it? I should have filtered on the "Central" Region instead of the specific person.
DeleteThe article is a rare case of looking at Tableau through SQL lenses. I put it into my spaced repetion cards, so, forgive me for having questions over and over again. 'Spaced' indeed. ))
ReplyDeleteNow, I lost the understanding why we use INNER JOIN twice.
Instead of
SELECT [Customer Name], SUM([Sales])
FROM [Orders]
INNER JOIN (
SELECT [Orders].[Region]
FROM [Orders]
INNER JOIN [People_Multiple]
ON [Orders].[Region] = [People_Multiple].[Region]
WHERE [Person] = 'Central Person 1'
GROUP BY [Orders].[Region]
) AS [Table 1]
ON [Orders].[Region] = [Table 1].[Region]
GROUP BY [Customer Name]
I use
SELECT [Customer Name], SUM([Sales])
FROM [Orders]
INNER JOIN (
SELECT [People_Multiple].[Region]
FROM [People_Multiple]
WHERE [People_Multiple].[Person] = 'Central Person 1' //or whatever
GROUP BY [People_Multiple].[Region]
) AS [Table 1]
ON [Orders].[Region] = [Table 1].[Region]
GROUP BY [Customer Name]
I don't see the difference. There mustn't be duplication due to "GROUP BY [People_Multiple].[Region]". What do I miss here?