
SQL for Tableau Part 3: Aggregation

Part 1 of our series on SQL for Tableau dealt with the basics and part 2 dealt with combining data via joins and unions. In part 3, we’ll be talking about aggregation.
Quick reminder before we jump in—the data we’ll be using is on a publicly available SQL Server database built from the latest Tableau Superstore data. For more details on connecting to the database see part 1.
Aggregation
Aggregation is the process of performing some calculation on a set of values in order to return a single value. As Tableau users, you are already very familiar with this concept because it’s a critical part of building Tableau visualizations—we regularly aggregate data using SUM, MAX, MIN, AVG, MEDIAN, COUNT, COUNTD, etc. Ultimately, this is quite similar to how it’s done in SQL.
To aggregate data in SQL, you’ll use an aggregate function. Here’s the basic syntax:
SELECT <Function>(<Field Name>) FROM <Table Name>
Just like Tableau, we call a function, then pass values to that function. As an example, let’s say you want to find the earliest date in the Superstore Orders table. You could do this:
SELECT MIN([Order Date]) FROM [Orders]

And you could find the latest order date by doing this:
SELECT MAX([Order Date]) FROM [Orders]

Of course, if you needed to find both the earliest and latest dates, you could combine these into a single SQL statement as follows:
SELECT MIN([Order Date]), MAX([Order Date]) FROM [Orders]

Notice that neither of the columns have an actual name—they both say “No column name” in the header. This is because we’ve created these columns from scratch and need to explicitly name them. To do that we’ll use column aliases as we discussed in part 1.
SELECT MIN([Order Date]) AS [First Date], MAX([Order Date]) AS [Last Date] FROM [Orders]

Aggregate Functions
The most common aggregate functions in SQL are the following (all are part of the ANSI standard):
• AVG – Calculates an average
• COUNT – Counts the number of rows
• MIN – Calculates the minimum value
• MAX – Calculates the maximum value
• SUM – Calculates a sum of all values
There are many more aggregate functions available including ranking functions and various statistical functions, but we won’t be dealing with those here. You can read about all the functions here: ANSI SQL Aggregate Functions.
Note: As you can see, Tableau uses many of the same names as SQL functions, so if you know a function in Tableau, it’s very likely that SQL will use the same function name (and vice versa).
There are, however, a few glaring omissions. What about MEDIAN? Strangely, enough, median is not part of the ANSI SQL standard. Some database platforms, such as Oracle (version 10g forward), include a median aggregate function, but many, if not most, do not (Note: There are still ways to calculate it, but they require you to perform multiple subqueries and aggregations). If you realize it or not, this has a direct impact on you when you’re working with Tableau. Ever try to calculate a median on a live connection to SQL Server, MySQL, or Teradata? If you do, you’ll get an error. This is because live connections must execute SQL against the database and, if the database does not support a median function, this cannot be easily done. For more on this, see the Tableau knowledgebase article, Median Function Not Available.
You may also be asking about a count distinct function, something that is used quite heavily in Tableau. Fortunately, this can be done SQL, but it will require introduction of the DISTINCT key word, which we’ll get to later in this post.
We’ve already seen examples of MIN and MAX, so let’s look at a couple examples of the remaining commonly-used aggregate functions. We’ll start with COUNT, which counts the number of rows. This is a bit of a strange one because you don’t always necessarily need to execute the count against a specific column. You could just choose an arbitrary column, such as:
SELECT COUNT([Row ID]) AS [Order Count] FROM [Orders]

But, this function isn’t really doing anything specific with Row ID, so we can actually simplify this by using an asterisk:
SELECT COUNT(*) AS [Order Count] FROM [Orders]
Like the first example, this will also return 9994 records. Which you use is up to you, but I personally prefer the second simply because it removes any confusion that the function is operating on that specific field.
For the next example, let’s say that your supervisor asks you to analyze the superstore sales data. She has three questions:
1) What were the total sales for 2017?
2) What were the average sales amount per order line?
3) How many total order lines were there?
We can do this pretty easily in a single SQL statement. Give it a try…
Got it? It should look something like this:
SELECT SUM([Sales]) AS [Total Sales], AVG([Sales]) AS [Average Sales], COUNT(*) AS [Order Count] FROM [Orders] WHERE [Order Date]>='01/01/2017' AND [Order Date]<='12/31/2017'

At this point, hopefully you’re starting to feel comfortable with the basics of aggregation, but you’ve probably noticed that every SQL example above aggregates all the records based on our criteria. While you’ll need to do this from time to time, it’s more likely that you’ll want to aggregate based on dimensions in your data. For that, we’ll use GROUP BY.
GROUP BY
GROUP BY allows us to specify the level of detail at which we wish to aggregate our data. Essentially, it just groups all like data for the specified dimension(s), then performs the aggregation separately for each group. Clear as mud? Hang on, we’ll get there. Let’s take a look at the basic syntax:
SELECT <Function>(<Field Name>) FROM <Table Name> GROUP BY <Grouping Field List>
For example, after you answered your supervisor’s high-level question about sales, she now wants to dig a bit deeper, so she asks for the total sales by customer. For this, we’d write the following SQL:
SELECT [Customer Name], SUM([Sales]) AS [Total Sales] FROM [Orders] WHERE [Order Date]>='01/01/2017' AND [Order Date]<='12/31/2017' GROUP BY [Customer Name]

But what if we wanted to look at sales for each customer and product category that the customer purchased? Let’s start by just adding Categoryto the select list:
SELECT [Customer Name], [Category], SUM([Sales]) AS [Total Sales] FROM [Orders] WHERE [Order Date]>='01/01/2017' AND [Order Date]<='12/31/2017' GROUP BY [Customer Name]
Unfortunately, if you run this, you’ll get the following error:
Column 'Orders.Category' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
Uh oh! What happened? You’re getting this error because you’ve specified Category in the select list but not in the group. Because you are only aggregating by the Customer Name (it’s the only thing in the GROUP BY clause), the Category field could potentially contain multiple values. SQL won’t allow this.
A quick side note: As you know, Tableau actually does allow this (kind of). Let’s say you have a simple view showing sales summed by customer as follows:
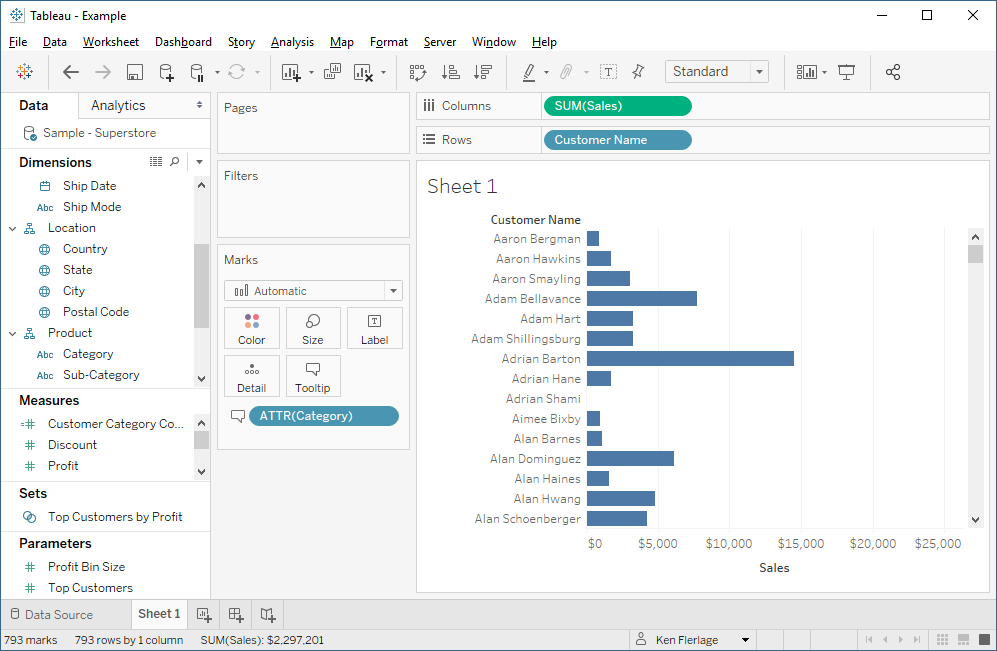
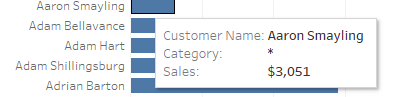
If you like, you can still place Categoryon the view. Perhaps you place it on the tooltip card. When you do that, Tableau will wrap the field with ATTR. As detailed quite well in an article by the folks at Interworks, ATTR essentially tests a value to see if it is unique; if it is, it returns the value; otherwise, it returns *. So, if you then hover over a customer who purchased multiple product categories, you’ll get the asterisk.
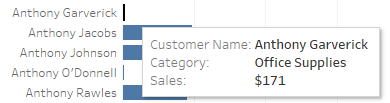
But, if the customer only purchased a single category, you’ll get that value.
While this tangent doesn’t solve the fact that SQL will not allow this, I just want to illustrate the similarities (and differences) between how Tableau and SQL work.
Okay, back to to SQL…before going on that tangent, we had the following invalid SQL:
SELECT [Customer Name], [Category], SUM([Sales]) AS [Total Sales] FROM [Orders] WHERE [Order Date]>='01/01/2017' AND [Order Date]<='12/31/2017' GROUP BY [Customer Name]
As noted, SQL will not allow us to include a field in the select unless it is either included in the group or it is itself an aggregate. So, in this case, we must add it to the group, as follows:
SELECT [Customer Name], [Category], SUM([Sales]) AS [Total Sales] FROM [Orders] WHERE [Order Date]>='01/01/2017' AND [Order Date]<='12/31/2017' GROUP BY [Customer Name], [Category]

HAVING
As we’ve shown above, we can add criteria/filters to SQL that includes aggregation, but what if we want to add criteria on the aggregated value itself? For example, perhaps we wish to find any customer in 2017 who has a total sales of over $10,000? We could try putting it in the WHERE clause…
SELECT [Customer Name], SUM([Sales]) AS [Total Sales] FROM [Orders] WHERE [Order Date]>='01/01/2017' AND [Order Date]<='12/31/2017' AND SUM([Sales])>10000 GROUP BY [Customer Name]
But this will give us the following error:
An aggregate may not appear in the WHERE clause unless it is in a subquery contained in a HAVING clause or a select list, and the column being aggregated is an outer reference.
To filter on an aggregate value, we must use HAVING. Here’s the syntax.
SELECT <Function>(<Field Name>) FROM <Table Name> GROUP BY <Grouping Field List> HAVING <Condition>
So, our SQL above could be written as follows:
SELECT [Customer Name], SUM([Sales]) AS [Total Sales] FROM [Orders] WHERE [Order Date]>='01/01/2017' AND [Order Date]<='12/31/2017' GROUP BY [Customer Name] HAVING SUM([Sales])>10000

DISTINCT
While DISTINCT isn’t specific to aggregation, it can be quite useful, so I’ll introduce it quickly here. The DISTINCT key word simply tells the database that we wish to select only unique values from the database. DISTINCT will always go before your field list. For example, the following will retrieve a list of distinct customers from the Orders table:
SELECT DISTINCT [Customer Name] FROM [Orders]
So, while each customer can have multiple records in the table, this SQL will only give you each customer name once.
This can be valuable for everything from eliminating duplicate records in your data to profiling your data to better understand specific dimensions, their frequencies, etc. And, it can also be quite useful if you wish to perform a distinct count as we alluded to earlier. To do this, we simply place the DISTINCT keyword before our field, but within the aggregate function. For example:
SELECT COUNT(DISTINCT [Customer Name]) AS [Customer Count] FROM [Orders]

Coming Up…
Before closing this out, I do want to mention that everything you are learning can be combined together. For the sake of simplicity, I’ve avoided making our SQL overly complex, but just be aware that aggregation can be combined with use of ORDER BY to sort your results and can leverage joins and unions. If you have time, come up with a few use cases and give it a try.
Thanks for reading. For part 4, I’ll be handing the reins over to guest author Robert Crocker, so stay tuned!
Ken Flerlage, October 1, 2018























hi when is the next part coming and what are the other stuff you should know about sql that we havent covered in part 1,2 and 3
ReplyDeleteThe next part should be coming in 2 weeks. Not sure of the topic yet. If you look at the end of part 1, you'll see the different topics we hope to cover at some point.
DeleteI love how you are doing this;'I just want to illustrate the similarities (and differences) between how Tableau and SQL work.'
ReplyDeleteNice series. You might want to highlight more clearly how Count() functions though. It does not just count the number of rows as in the case of Count(*)
ReplyDeleteCount([Field X]) returns the number or rows that have a non-null value for [Field X]
So select count(spouse_name) from employee returns the number of married employees
Am I reading it wrong or missing a hyperlink or something?
ReplyDeleteI thought this article was about how I can mimic SQL aggregation actions in Tableau; especially GROUP BY but all I could find was how to do aggregation in SQL. I feel like I am missing some point of this article.
This is a blog about SQL, targeted at Tableau users who may not have much experience with SQL. If you read part 1 (linked in the beginning), it makes the following explanatory statement:
DeleteI have always worked in Information Technology (as opposed to the “business” side) and I spent many years as a SQL Server DBA. I have also spent years building data warehouse models, so I have a pretty deep understanding of SQL. However, many Tableau analysts do not have similar backgrounds, so this series of blog posts will attempt to provide a primer to SQL, with a specific focus on Tableau users. That being said, I hope that it will also prove a useful guide to others as well. Just be aware that I’ll often refer back to Tableau throughout the series. If you’re okay with that, then read-on; if not, then there are lots of other SQL resources out there that may be more applicable to you.
Hi Ken , Great series. Thanks for taking the time to document and for sharing your knowledge.
ReplyDeleteI was wondering if part 4 and beyond are out yet?
Parts 4, 5, and 6 are on the site. Just look at the SQL tag on the site: https://www.flerlagetwins.com/search/label/SQL?&max-results=6
DeleteLearning about 2 languages in one article, its awesome, thanks you for your efforts!
ReplyDelete